
Introduction
Machine learning has become a pivotal technology in numerous industries, from healthcare to finance, driving innovation and efficiency. According to a recent report, the global machine learning market is expected. To reach $117.19 billion by 2027, growing at a CAGR of 39.2%. Machine Learning Algorithms
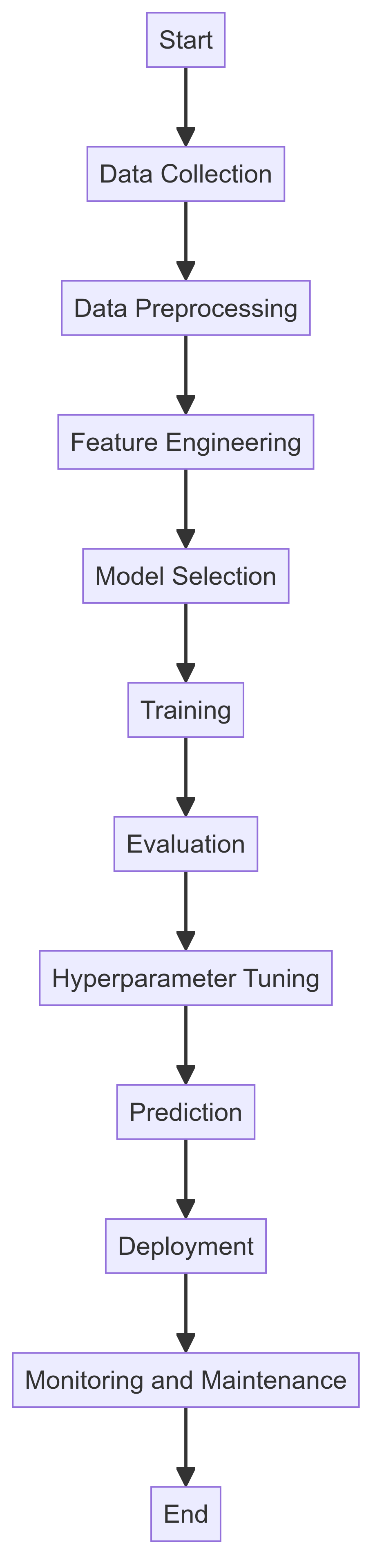
Machine learning, a subset of artificial intelligence, focuses on the development of algorithms that enable computers to learn from and make decisions based on data. These algorithms are the engines behind various predictive and analytical tasks, automating processes and enhancing decision-making.
This article aims to provide a comprehensive guide to understanding machine learning algorithms. We will delve into the different types of machine learning algorithms, their applications, and the methodologies for selecting and implementing them effectively.
Basics of Machine Learning Algorithms
Machine learning algorithms are computational methods that enable systems to learn patterns from data and make decisions or predictions without explicit programming. These algorithms are fundamental to the functioning of machine learning models.
The importance of machine learning algorithms lies in their ability to process large volumes of data. Identify patterns, and generate insights that can be used for decision-making. They are essential for tasks such as classification, regression, clustering, and anomaly detection.
Machine learning algorithms can be broadly classified into four categories:
- Supervised Learning: Algorithms trained on labeled data to predict outcomes.
- Unsupervised Learning: Algorithms that identify patterns in unlabeled data.
- Semi-supervised Learning: Combines a small amount of labeled data with a large amount of unlabeled data.
- Reinforcement Learning: Algorithms learn by interacting with an environment to maximize cumulative reward.
Understanding these categories helps appreciate the diversity and capabilities of machine learning algorithms in solving complex problems.
Supervised Learning Algorithms
Supervised learning is a type of machine learning where algorithms are trained using labeled data. The model learns to map input data to the desired output. Making it suitable for tasks where the output is known.
Supervised learning algorithms are widely used. In various applications, including:
- Spam detection in emails.
- Fraud detection in financial transactions.
- Image classification in medical diagnostics.
- Sentiment analysis in customer feedback.
These algorithms are powerful tools for predictive modeling, enabling businesses and organizations to make informed decisions based on data.
Linear Regression
Linear regression is a method used to predict a continuous dependent variable based on one or more independent variables. It fits a linear relationship between the input variables and the output.
Logistic Regression
Logistic regression is used for binary classification problems, predicting the probability of a binary outcome. It’s commonly used for tasks like disease diagnosis (e.g., predicting whether a patient has a specific disease).
Decision Trees
Decision trees create a model that predicts the value of a target variable by learning simple decision rules inferred from data features. They are easy to interpret and can handle both categorical and continuous data.
Support Vector Machines (SVM)
SVMs classify data by finding the hyperplane that best separates the classes in the feature space. They are effective for high-dimensional spaces and are used for tasks such as text classification.
Neural Networks
Inspired by the human brain, neural networks are used for complex tasks. Such as image and speech recognition. They consist of interconnected layers of nodes (neurons) that process data in a hierarchical manner.
Unsupervised Learning Algorithms
Unsupervised learning involves training algorithms on unlabeled data. The goal is to identify underlying patterns or structures in the data without predefined labels or categories.
Unsupervised learning algorithms are essential for exploratory data analysis and discovering hidden structures in data. They are used in:
- Customer segmentation for targeted marketing.
- Anomaly detection in network security.
- Gene expression analysis in bioinformatics.
- Market basket analysis in retail.
These algorithms provide valuable insights into data, helping businesses understand their customers and optimize operations.
K-Means Clustering
K-Means clustering partitions data into K distinct clusters based on feature similarity. It’s widely used for market segmentation and image compression.
Hierarchical Clustering
Hierarchical clustering creates a hierarchy of clusters by iteratively merging or splitting existing clusters. It helps in understanding the data’s structure and relationships.
Principal Component Analysis (PCA)
PCA is a dimensionality reduction technique that transforms data into a new coordinate system, highlighting the most significant features. It’s used for data visualization and noise reduction.
Anomaly Detection
Anomaly detection identifies rare or unusual data points that do not conform to the general pattern of the data. It’s crucial for fraud detection and monitoring systems for faults.
Semi-supervised Learning Algorithms
Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data during training. This approach is beneficial when labeled data is scarce or expensive to obtain.
Semi-supervised learning algorithms are used in various domains, such as:
- Speech recognition, where transcribing audio data is costly.
- Text classification, with large corpora of unlabeled text.
- Image classification in medical imaging, where labeling requires expert knowledge.
By leveraging both labeled and unlabeled data, these algorithms improve model accuracy and efficiency.
Self-training
A simple approach where a model is initially trained on labeled data. And then used to predict labels for the unlabeled data. The model is retrained iteratively, improving its performance.
Co-training
In co-training, two models are trained on different views of the data. And then use each other’s predictions to label the unlabeled data. This method helps in leveraging complementary information from different data perspectives.
Graph-based Algorithms
Graph-based algorithms utilize the structure of the data represented as a graph to propagate labels from labeled to unlabeled nodes. These algorithms are particularly effective in scenarios where data points have inherent relationships, like social networks.
Reinforcement Learning Algorithms
Reinforcement learning (RL) involves training algorithms to make a sequence of decisions by interacting with an environment. The goal is to maximize cumulative reward over time.
RL algorithms are applied in various fields, including:
- Robotics, for learning complex motor tasks.
- Game playing, such as mastering chess and Go.
- Autonomous driving, for decision-making in dynamic environments.
- Finance, for optimizing trading strategies.
RL algorithms are powerful tools for solving sequential decision-making problems in uncertain environments.
Q-Learning
Q-Learning is a value-based method where the agent learns the value of actions in each state to derive an optimal policy. It’s widely used for problems where the model needs to learn a policy to achieve a goal.
Deep Q-Networks (DQN)
Combining Q-learning with deep neural networks, DQNs handle high-dimensional state spaces, making them suitable for tasks like video game playing, where the state space is vast and complex.
Policy Gradients
Policy gradient methods directly optimize the policy by estimating the gradient of the expected reward and adjusting the policy parameters accordingly. They are effective in environments where the action space is large and continuous.
Evaluating and Choosing the Right Algorithm
When choosing a machine learning algorithm, consider the following factors:
- Accuracy: The ability of the algorithm to make correct predictions.
- Training Time: The time required to train the model.
- Complexity: The complexity of the algorithm and its interpretability.
- Scalability: The ability to handle large datasets and scale with increasing data.
Compare the pros and cons of different algorithms based on these factors. For instance, linear regression is simple and interpretable but may not capture complex relationships. Neural networks, on the other hand, are powerful but require significant computational resources and expertise.
Tips for selecting the appropriate algorithm include:
- Start with simple algorithms and gradually move to more complex ones.
- Use cross-validation to assess model performance.
- Consider the domain and nature of the problem.
- Experiment with different algorithms and tune their hyperparameters.
By carefully evaluating and choosing the right algorithm, you can enhance the performance and efficiency of your machine learning models.
Conclusion
This article has provided a comprehensive guide to understanding machine learning algorithms. We discussed the basics, types, and applications of various algorithms, from supervised and unsupervised learning to semi-supervised and reinforcement learning.
Looking ahead, we can expect advancements in deep learning algorithms, the integration of machine learning with other AI technologies, and the development of more efficient and scalable algorithms.
As machine learning continues to evolve, it is crucial to stay updated with the latest trends and developments. Explore and experiment with different algorithms in your projects to unlock the full potential of machine learning.
that’s all for today, For More: https://learnaiguide.com/top-5-generative-ai-libraries-to-use-in-2024/